New Article in Nature Methods: Guiding questions to avoid data leakage in biological machine learning applications
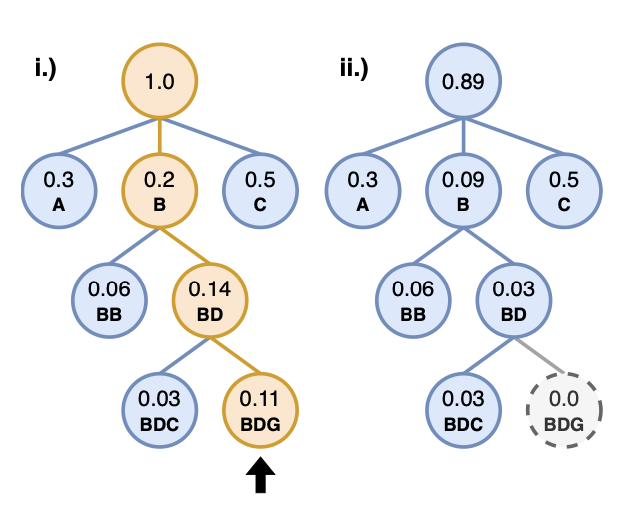
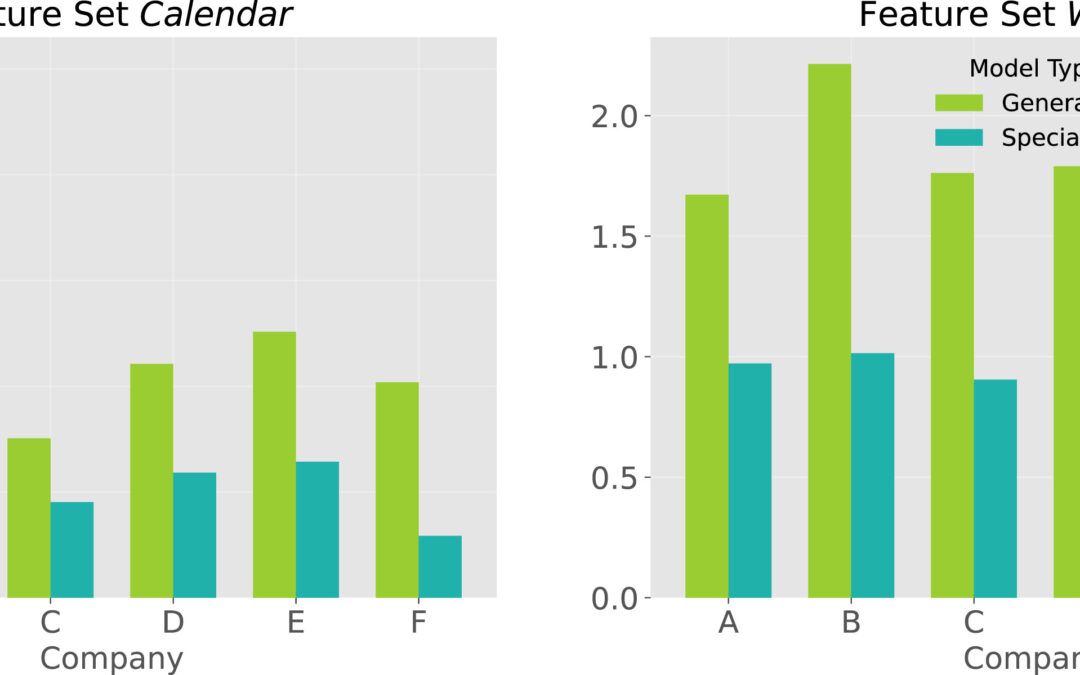
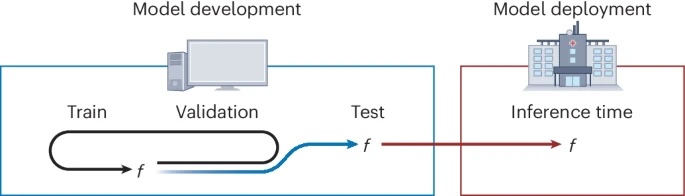
Artificial intelligence (AI) has become indispensable in biological research and is driving major advances. However, in certain cases, real-world applications fail to confirm reported predictive performance. One of the main reasons for this is data leakage, i.e. the unauthorized transfer of information between training and test data.
In this Nature Methods Perspective, we present seven questions that should be asked to prevent data leakage when constructing machine learning models in biological domains. By applying these questions to real examples in biology, we aim to make researchers aware of the complex latent interdependencies and possibilities of data leakage in biological applications. We strongly encourage researchers to engage in an interdisciplinary dialogue and to consult domain experts from both domains to ensure robust, reliable, and reproducible ML research in biology.